









Big Data
Research of Big Data Based on the Views of Technology and Application
Time:2017-02-23 Click:7530
Research of Big Data Based on the Views of Technology and Application
1. Introduction
Before big data appear, database has become an important processing platform because of the data processing convenience. But when database is faced with non-relational or large-scale data, there is a difficulty dealing with them. Big data not only enhance the related computing services technologies but also change the traditional mode of many industries. The latest report released by Markets and Markets shows that [1] , from 2013 to 2018, the annual compound growth rate of the global market for big data will be 26 percent, from $14.87 billion in 2013 to $46.34 billion.
Big data are the hottest words in the IT industry, followed by data warehouse, data analysis and data mining. The commercial value of the using big data gradually becomes the focus profits of different professionals. Big data help people acquire knowledge from the massive, complex data, and become another focus after integrated circuit and Internet information technology. IBM, Amazon, Microsoft and other large companies are constantly committed to develop and utilize big data, triggering the development boom of big data.
2. Development of Big Data
2.1. Definitions and Characteristics
The original concept of the idea of big data is from the world of computer science and econometrics [2] . Mc Kinsey & Company is the first company to refer big data. In June 2011, McKinsey issued a report on “big data”, which carried out a detailed analysis of the impact, key technologies and application. From that on, big data caused different industries’ concerns.
There are many kinds of definitions of big data. Wikipedia points out that big data usually includes data sets with sizes beyond the ability of commonly used software tools to capture, curate, manage, and process data within a tolerable elapsed time [3] . McKinsey believes that big data is one data set whose size exceeds the typical database software acquisition and storage, management and analysis. In Victor Meyer-Schonberg’s “BIG DATA” [4] , big data means using the method of all the data but not random analysis (sampling). IDC (International Data Corporation) is defined as to meet 4V (Variety, Velocity, Volume, Value) index called big data.
The characteristics of big data are submitted by Victor Meyer-Schonberg in “BIG DATA”. There are four characteristics, including volume, velocity, variety, value [4] .
Volume refers to the huge amount of data. With the development of data storage and network technology, data storage expands from TB to ZB. Only in 2011, 1.8ZB (1.8 trillion GB) of data are created. Warehouse management server will increase 10-fold to 50-fold to cater to the growth of big data. Velocity refers to the mobility of data streams. It is difficult to deal with data in a traditional way because data run fast. Through cloud computing, it can achieve fast data processing. Variety refers to relational and non-relational data generated by a variety of ways. With the development of mobile networks, people are more widespread to use real-time data. The quantity of semi-structured and non-relational data is also increasing. Value reflects the value of the significance of big data applications, which has a scarcity value, uncertainty and diversity.
All in all, although the definition of big data contains different concerns and technologies, but there is a consensus point, big data refers not only too large amounts of data, but also including a large amount of data processing techniques. “4V” characteristics show a large number of data. Volume, velocity and variety are aim to realize the value of big data. Data collection, storage, analyze, is prepare for dig out the value of data. Big data emphasizes complexity in data analysis, and it pays more attention to data processing efficiency and the data value.
2.2. Development Trend
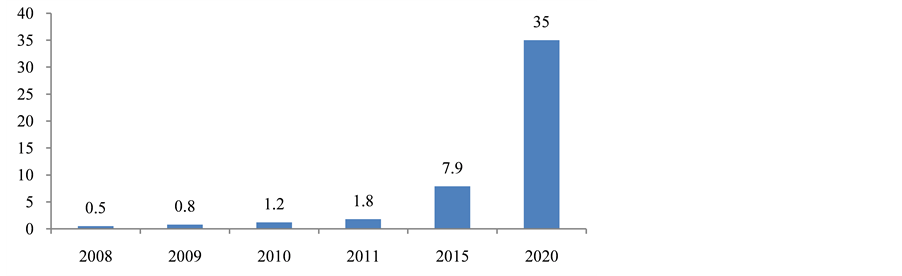
From an economic development perspective, many large companies focus on big data seriously. IDC’s report claimed that global data will increase by 50 times over the next decade, shown in Figure 1. Oracle President, Mark Hurd, said that now it’s the era of big data explosion, and data grew at an alarming rate. At present, the amount of data around the world is million trillion. Data increase 8 times from 2005 to 2011. In 2020, the expected amount of data could reach 35 million trillion.
The development trend of big data published in “2012 Hadoop and Big Data Technology Conference” showed the top three topics are: data resources, big data privacy issues and integration of big data and cloud computing. The magazine editor of Wired, Chris, has asserted that the data have made the traditional scientific method obsolete. Although this statement is a bit extreme, but big data indeed has changed our lives, our way of thinking. Big Data is widely used. Now many large companies use big data to streamline processes and create efficiencies, such as Microsoft, Apple, Oracle, Amazon, Google, FaceBook and Twitter. They are experienced in dealing with big data sets [5] .
3. Technologies
Big Data provides a new method to traditional data analysis, which has a variety of technologies, including Hadoop and MapReduce, cloud computing, grid computing and so on. This paper sorts out the following technologies.
3.1. Hadoop and MapReduce
In the related technologies, more representative one is Hadoop, which is represented by non-relational data
analysis techniques. By the virtue of processing for non-structural, massively parallel processing, easy using and other advantages, Hadoop becomes a mainstream technology. MapReduce is a model proposed for parallel processing and generating big data by Google in 2004 [6] , which is a linear, scalable programming model. Hadoop is an open source realization of MapReduce. With its open source and easy using, Hadoop has become the first choice for big data processing. It not only create targeted marketing applications, make full use of transaction data, but also improve accuracy and timeliness of fraud detection. Many Internet companies, including Facebook, Google, eBay and Yahoo, have developed a large scale applications based on Hadoop. MapReduce and Hadoop can significantly improve the efficiency of big data processing.
3.2. Big Data Acquisition Engine
In addition to the requirements of efficiency and speed, big data collection also requires security. A general data acquisition engine which combines rule engine and finite state automaton together, helps to verify the security and correctness of the big data acquisition flow [7] . When adding a new collection node, the rule engine will automatically make the whole system more flexible and scalable. At the same time, it ensures the state transition, and improves safety and clear logic. Big data acquisition, integrated with JESS rule engine, not only can control the state transitions and match, but also to monitor the unusual status and location errors. Rules engine can clearly show the errors and details which are matching wrong, ensure the safety and accuracy of the data acquisition.
3.3. MFA (Mean Field Analysis)
Big data processing system requires some related components to use in parallel multiple instances of the same task, so as to achieve the desired level of performance applications. In order to enable administrators and developers to maintain the growth rate of the data, these systems’ reliability assessment is critical. A set of methods for approximate inference of probabilistic models, based on MFA, can solve the performance evaluation system problem of big data [8] . Through behavioral modeling to assess the performance of data structure, MFA can calculate the related basic performance in a limited time. In addition, MFA can set up and evaluate in a shorter time, because it does not depend on the number of instances. In the process of assessing the performance of big data, MFA technology is very effective.
3.4. Other Technologies
In addition to the above-mentioned techniques, M2M (Machine To Machine) technology is an important one. M2M platform can expand the number of data producers and data consumers flexibility, accomplish new services in a very short period of time, re-use and combine data from different sources. Existing studies have shown that automatically creating M2M decision support system has much room for development [9] . There are also grid computing, cloud computing and other technologies in big data analysis and processing. Big data tech- nology is not a single technology, but mix with a variety of other techniques, so as to play the biggest role in the storage and analysis.
